A gentle introduction to four categories of AI models, and some suggestions on how education should approach its arrival.
Introduction
I’ve been doing computer graphics professionally for 25 years. I’ve never seen anything like generative artificial intelligence. Several years ago, on a motion capture stage, I saw the potential of real-time graphics and animation and was clobbered with the realization that AI would change everything.
This is a synopsis of a talk I gave to some students about the topic, and then, again, to animation and game development faculty. My interest here is to raise awareness.
This is intended for beginners with some understanding of computer graphics. It’s my hope today to give you an overview of four categories of AI that you should pay attention to, as it begins to permeate your life. At the end of this presentation, I give some thoughts on how education should adapt.
The six sections below are:
- It’s Only the Beginning
- Neural Networks
- Generative Models
- Large Language Models
- Foundational Models
- Thoughts on Education
It’s Only the Beginning
Below is a series of images that were created using AI. Most of these images were prompted, (which I will discuss below) and then generated by a clip diffusion model called Stable Diffusion.

Starting with image making and endless conversations with ChatGPT, AI has blended into almost all of my workflows. I’m now animating with it, writing with it, and in a constant experimentation cycle with it.
For example, I readily play with NERFs or Neural Field Radiance, which allow scanning full 3D objects for importing into the computer — with your phone! It’s amazing.
Here is a 3d NERF scan of my 7 year old’s Lego ATAT. Let it load – You can grab and rotate around it.
These kind of accessible software tools for creation will proliferate rapidly. The graph below from venture capitalist firm Andreessen Horwitz shows that the number of research papers with working code has skyrocketed. These research innovations, some included below, are becoming productized.
In short, computer graphics is becoming accessible to everyone.

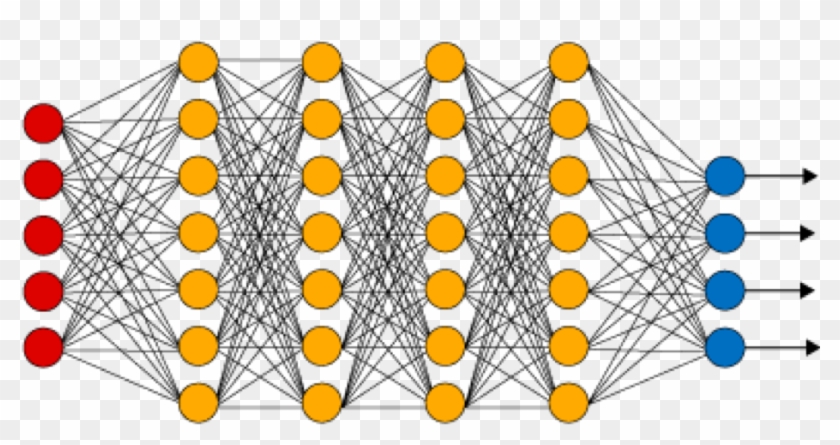
Neural Networks
Learning Goal: Understand how to build a Classifier.
Artificial Intelligence is a science that is several decades old. It is most likely that the architecture of the neural network, in addition to the creation of insanely vast amounts of internet data, has been the rocket fuel for the discipline to explode.
Neural networks can see and learn patterns.
When you unlock your phone with your face, it is a neural network that recognizes you. Neural networks are critical primitive for the generative artist to learn.


Above is a pixelated orc. Every pixel on this image has an x value and a y value, and it is either black or white. A pixel then, is just numbers. With these numbers put together with other pixels, we can create a pattern, like a simple 3×3 diagonal. A collection of this math that recognizes this pattern is attached to a “little activation unit.” These activation units fire when sensing simple patterns. These units are called “neurons.”
Neural networks are rowed collections of these neurons. A series of pattern activators spread over a series of layers. To build one is to “train” the neurons and “tune” the math between the layers. This is done by feeding it lots of data on the patterns you wish it to learn.
It is effectively a way for math to have memory.

Neural networks are widely used for object classification, image segmentation and all sorts of useful pattern recognition.
Demo: Build a Power Ranger Classifier
In the demonstration below, I show how machine learning can learn to recognize my five year old’s Power Ranger. After running the trained model, I show the two data sets: One with the Power Ranger, and the other without.
By learning the patterns of each of these datasets, we can recognize a Power Ranger.
Try Lobe yourself at Lobe.ai
Generative Models
Learning Goal: Understand how to prompt and tune generative image making models.
Have you used ChatGPT? How about Midjourney?
These are generative models. These models take input and generate an image or text. Eventually, this method will be used to create … well, potentially anything digital. This input is called “Prompting.” Prompting is a form of user intent, a sentence that represents what we hope the AI model will generate for us.
In this case, my prompt was for a painting of George Washington drinking a beer. I use references to artists to get it closer to my desired output. (I’ll leave the intellectual property discussion for another day.)

It’s not bad, huh? And it’s gettin’ pretty good. But, prompting has it’s limits.
I can’t make an image of me as Iron Man by just prompting alone. It doesn’t know what I look like. Which is why I need to tune a dataset on the images of me. This means creating a dataset of me, say 25 pictures or so, and then feeding it to the network so it learns to identify that pattern. (Me!) This can be a little challenging, but the tooling is getting better.


Once I’ve trained the model, however, I’m able to use it with any other prompt quite easily. And since clearly there is a real need to turn myself into a Pixar character, I can easily do that.
Learning to tune generative models is a fundamental skill for the generative artist.
A quick note on Latent Space …
Latent Space is a concept that helps me understand data sets as a giant universe of data. Each of these colored dots might represent a vector, or a specific category, of the dataset. Say “anime” or “science fiction,” or specific to the camera like “cinematic.”

The intersection of these vectors is what generates a unique seed of a pattern. This pattern is an absolutely new and unique generative image.
Demo: Image Making with Stable Diffusion.
As an animator, of course I am interested in robots. Giant robots. When I began using image generation models, I began prompting mechs and science fiction.

When I began, I used the image creation model, Disco Diffusion in Google collab notebooks. A year later, I am now creating more compelling imagery with the more robust and accessible, Stable Diffusion. By using the platform Leonardo.ai I can iterate far quicker than I ever did in the Google collabs.
This is evidence that coherence and fidelity of images will only accelerate with better models, tooling and workflow.

I recommend prompting images yourself with the Stable Diffusion platform Leonardo.ai.
Large Language Models
Chat GPT, and similar models like Google Bard and called large language models. They are composed of a giant transformer. Not like Optimus Prime, but like a huge predictive network that chooses the next word in the sentence. You know how your email suggests a response? ChatGPT is the mega-mega version of that.
However, in addition to the transformer, it also learns to understand you. Natural language processing is a species of AI that learns how to understand the intent, or underlying meaning, of the sentence. The bigger and better the model, the better it “understands” you.

Large Language Models have the potential to be THE MOST disruptive technology of the bunch. Because they are text, they can increasingly understand and generate code, essays, books, scripts, emails, and spreadsheets. When they become what’s called “multi-modal” they will probably also generate films, games, animation curves and 3d assets.
If you haven’t already started using ChatGPT, I highly recommend you start. Learning to prompt LLM’s in your discipline and workflow will be critical.
Foundational Models

In a recent interview, Sam Altman, the CEO of Open AI, foretold a vision of how companies with multimillion-dollar processing power will sit at the base of a new artificial intelligence software ecosystem. A gold rush of smaller companies, will use the APIs and “tune” these massive models to provide customizations for specialized markets.
These giant models are called “foundational models.”
We need to think of this disruption as a new operating system. The base of will be where custom datasets are tuned into it. Like I trained myself into the Iron Man picture, we all will train our custom data into a foundational model. Our decision, then, will be which one to use.
These large text models are currently owned by big companies like Open AI, Amazon, and Elon Musk’s new X.ai. The graphics models which contain imagery and animation data are also growing to robustness within the servers of Adobe and NVidia.

NOTE: Since giving this presentation, Stability.ai has gained massive traction on Git Hub, localizing Open Source alternatives. Should this decentralization continue, we may see a trend towards localized models instead of foundational models. It’s too early to tell, but indicative of a field that is moving at light speed.

So let’s review…
Neural networks are used for pattern recognition and prediction. Generative models query latent space to generate useable text, images, (and soon) may other things. LMMs are the real disruption of intelligence software.
Foundational models are the architectural base, that everything will be built from.
It will be up to us to tune our data sets, to fit our specific needs.
Wonder Dynamics Demo
The following is a demonstration of the cloud-based software, Wonder Dynamics. This is a promising workflow for the feature film or visual effects artist. You’ll hear that my five year old is just as impressed with the robots as I am.
Try Wonder Dynamics yourself by signing up for early access.
Education
Education will need to adapt to be relevant in an AI world. Here are three suggestions.

Documentation
First, we must double down on documentation. I encourage students to use artificial intelligence, but they MUST document their process.
If they start passing off AI for their own work, that’s cheating. However, well documented work flow is just good practice. Learning documentation is important for them to internalize concepts like attribution, licensing and intellectual property.

Data Sets
We must learn to create our own protected datasets. We must also learn to be aware of terms of use. Using stolen data can lead to lawsuits and a variety of really bad outcomes.
My livelihood will be my animation curves. Your livelihood, be it concept artist, or writer, will be the information that you create to train your specific models for production.
Your AI data will need to reflect your work and style. And that data (and your individuality) will need to be protected.

Mind Set
We need to change our focus from localized applications and start thinking about the interoperable networked one. Software won’t be architected locally, but increasingly will be a series of trained datasets, most likely in the cloud.
When I speak with people about the future of artificial intelligence, and the concerns about automation, I’m often asked:
“What’s left for us to do?”
The only thing I’ve can come up with is creativity, ideas and community.
My hope is that if we stay true to these principles, we will maintain a human value in a world where our labor is automated.
(Fin)

For the just getting started
Some great learning resources that really helped me out when I was first learning about AI.
- Artificial Intelligence, A Guide to Thinking Humans by Melanie Mitchell – A non-technical, high school level read about the topic. Her chapter on neural networks was particularly useful.
- Super Intelligence: Paths, Dangers, Strategies by Nick Bostrom – A philosophical meditation on the arrival of AGI. Extremely useful for understanding model training, and the dangers of the intelligence “take off.”
- Two Minute Papers Youtube Channel by Dr. Zsolnai-Feher – An upbeat optimistic computer scientist shows off the amazing advances of AI research. “What a time to be alive!”
- ML4A – Machine Learning for Art by Gene Kogan – One of the OG’s of generative image making shares his class videos, notes and github repos in this introductory series on machine learning, specifically for art.
- Linear Algebra Video Lectures by Dr. Gil Strang – An enthusiastic explanation of a complex mathematical subject by one of MIT’s best professors. Just understanding the basics of vectors is a huge leverage in AI.
This presentation and supporting materials are licensed under creative commons as an Attribution-NonCommercial-ShareAlike 4.0 International. (For more information: CC BY-NC-SA 4.0)